This morning I noticed that one of the Hyper-V Hosts at a customer were logging this error regularly in the system Eventlog;
|
|
Error 5/19/2015 7:40:14 AM Service Control Manager 7023 None The Interactive Services Detection service terminated with the following error: Incorrect function. |
The full detailed entry:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
Log Name: System Source: Service Control Manager Date: 5/19/2015 7:40:14 AM Event ID: 7023 Task Category: None Level: Error Keywords: Classic User: N/A Computer: FAHOST03.fabric.xxxxxxxxxx.com Description: The Interactive Services Detection service terminated with the following error: Incorrect function. Event Xml: 7023 0 2 0 0 0x8080000000000000 223591 System FAHOST03.fabric.xxxxxxxxxx.com Interactive Services Detection %%1 5500490030004400650074006500630074000000 |
It looks like the events are happening every 30 minutes, and at the same time as Windows is for some (so far) unknown reason doing a reinstall of a lot of MSI packages, and the above Interactive Service is triggered at the same time as it’s reinstalling the DHCPExt.msi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
Log Name: Application Source: MsiInstaller Date: 5/19/2015 7:40:14 AM Event ID: 1035 Task Category: None Level: Information Keywords: Classic User: FABRIC\SVC-VMM_ADM Computer: FAHOST03.fabric.xxxxxxxxxx.com Description: Windows Installer reconfigured the product. Product Name: Microsoft System Center Virtual Machine Manager DHCP Server (x64). Product Version: 3.2.7768.0. Product Language: 1033. Manufacturer: Microsoft Corporation. Reconfiguration success or error status: 0. Event Xml: 1035 4 0 0x80000000000000 223173 Application FAHOST03.fabric.xxxxxxxxxx.com Microsoft System Center Virtual Machine Manager DHCP Server (x64) 3.2.7768.0 1033 0 Microsoft Corporation (NULL) 7B46434337463337462D463635352D343437352D394130342D3239423142463731444639397D3030303063613232326561376464646365306534303839613538386434636362343261633030303030393034 |
I can so far unfortunately not find anything that’s logging why Windows is reconfiguring all MSI Packages on the server every 30 minutes.
It does look like it’s the DHCP Server extension that’s causing the Interactive Service errors, as they always happen at the same time. Though, the DHCP Server extension shouldn’t be reconfiguring in the first place.
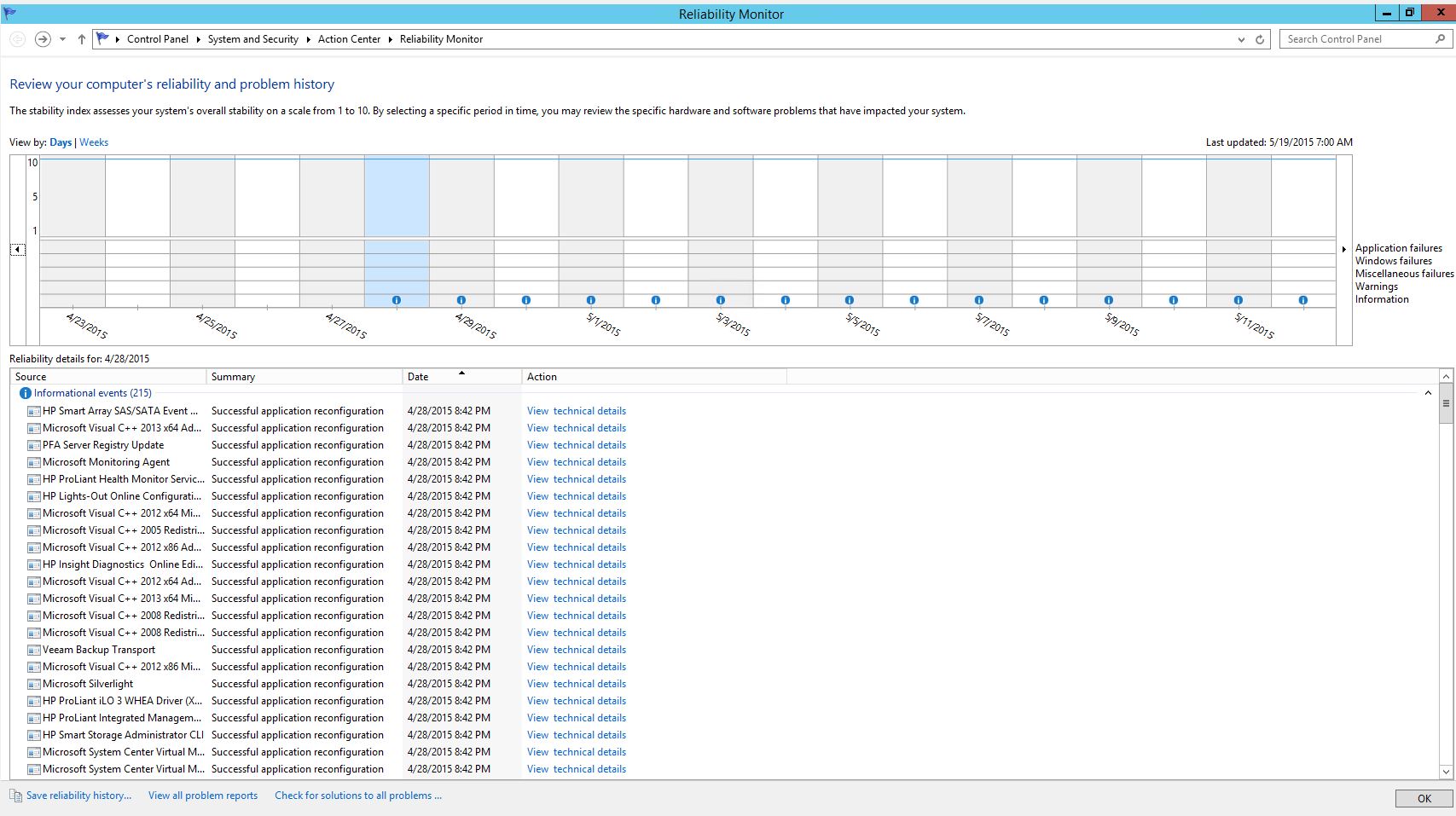
We always enable the Reliability History on all servers whi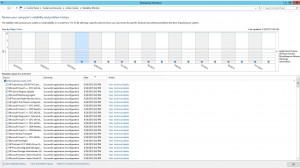 ch can be handy at times to see when a problem begun happening.
ch can be handy at times to see when a problem begun happening.
Check this Out!
It looks like the problem started on April 28 at 8:42 PM.
As the Reliability History tool is disabled by default, I’ll make another blogpost showing how you can enable this feature for all your servers.
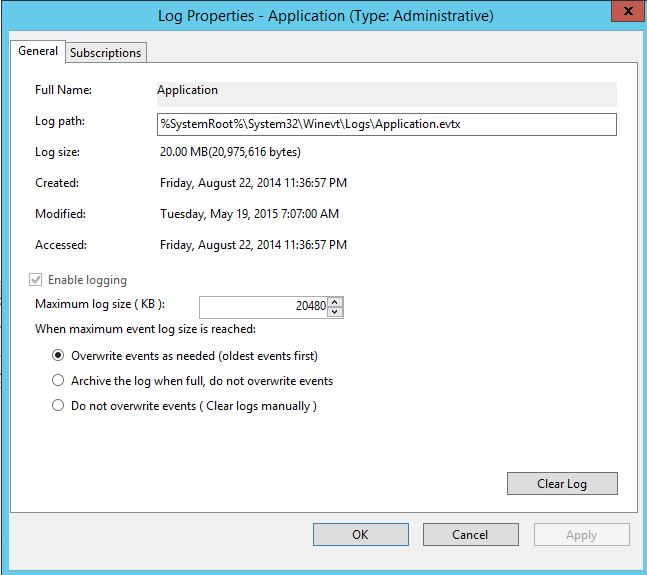
W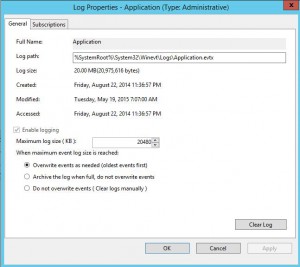 hen I wanted to see what had happened around April 28th. I noticed that was the oldest entries in the Application log. When the log has become full, it has removed the oldest entries according to the settings.
hen I wanted to see what had happened around April 28th. I noticed that was the oldest entries in the Application log. When the log has become full, it has removed the oldest entries according to the settings.
So I don’t think I’ll get any more details that way, and it does look like this problem has gone on for quite some time.
I’ll just reinstall the Hyper-V Host as it’s done in a few minutes compared to spending hours trying to fix the problem.
AND… I’ll create a Group Policy that will increase the Eventlog Size to x10 the default. So the next time something like this happens, I’ll have information to dig deeper.
Updated 2015-05-19 09:08:
After doing some more digging, it seems according to this KB Article (KB974524 : Event log message indicates that the Windows Installer reconfigured all installed applications) that this problem can happen if one of the following is true:
- You have a group policy with a WMIFilter that queries Win32_Product class.
- You have an application installed on the machine that queries Win32_Product class.
As the problem is not happening every 90-120 minute which would be true if it was GPO Triggered, I would say it’s an application that uses the Win32_Product class. And after doing some digging, it turns out it’s a known problem with VMM which will be fixed in UR7. Or hopefully earlier with a hotfix.
Updated 2015-05-19 10:12:
Wow, I got a hotfix for the issue within 15 minutes after contacting the VMM Team.
I’ve just installed it in our test environment and will later install it in the customers production environment.
Unfortunately I don’t have a KB or Hotfix ID for this, but if you contact Premier Support I think you can mention that you need a hotfix for Engine.Adhc.Operations.dll which gives support for RegKey: UpdateDHCPExtension
That info should make them able to find the correct hotfix.